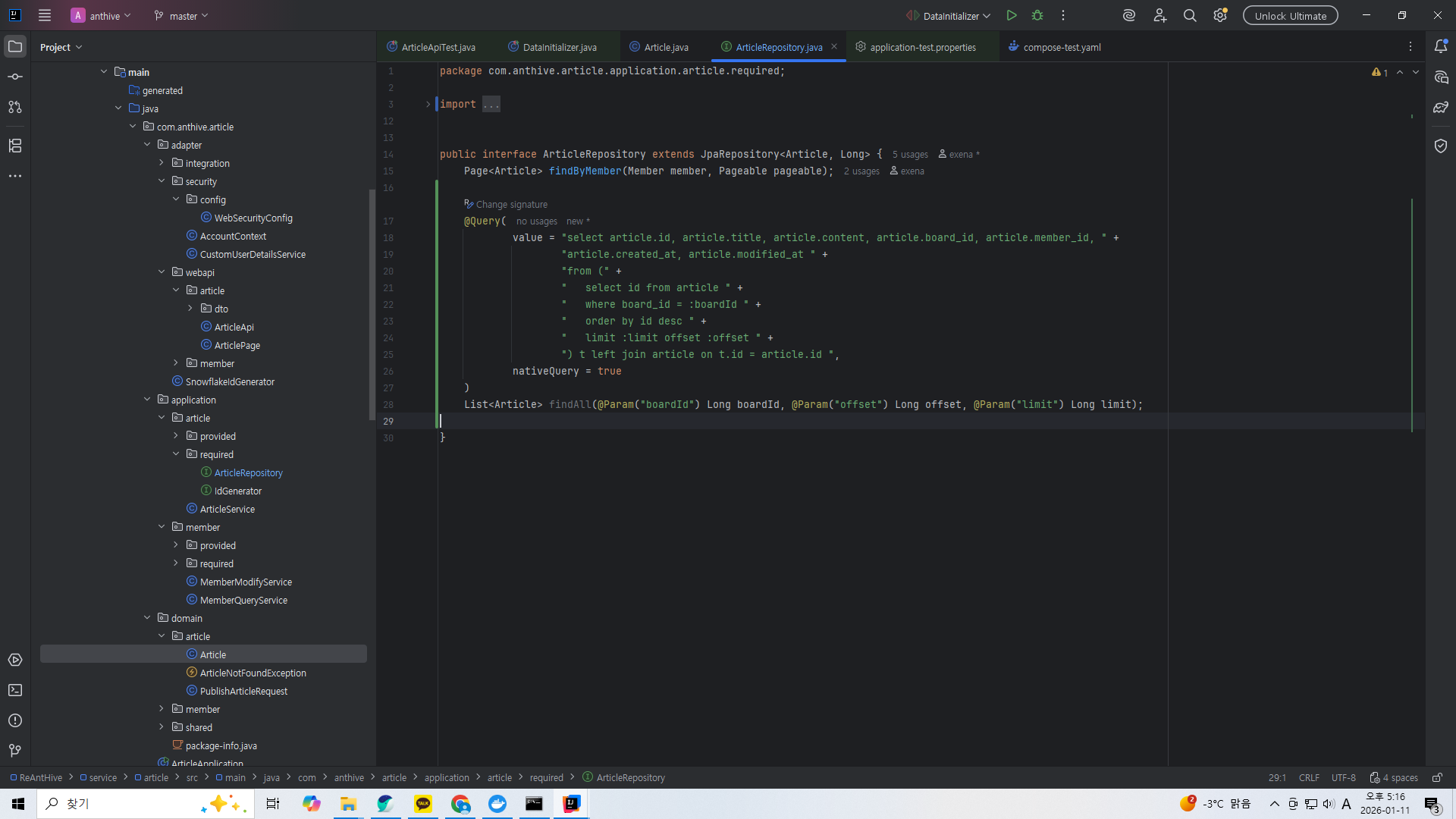
@Query(
value = "select article.id, article.title, article.content, article.board_id, article.member_id, " +
"article.publish_date " +
"from (" +
" select id from article " +
" where board_id = :boardId " +
" order by id desc " +
" limit :limit offset :offset " +
") t left join article on t.id = article.id ",
nativeQuery = true
)
List<Article> findAll(@Param("boardId") Long boardId, @Param("offset") Long offset, @Param("limit") Long limit);이전 포스팅에서 썼던 offset과 limit로 서브쿼리를 써서 커버링 인덱스로 일정 범위의 데이터 목록을 가져오는 방식을 써서 특정 페이지의 게시글 목록을 가져오도록 하겠다.
위에 있는 함수를 보면 Spring Data JPA에서 제공하는 Pageable을 사용해서 특정 페이지의 게시글 목록을 불러왔었다.
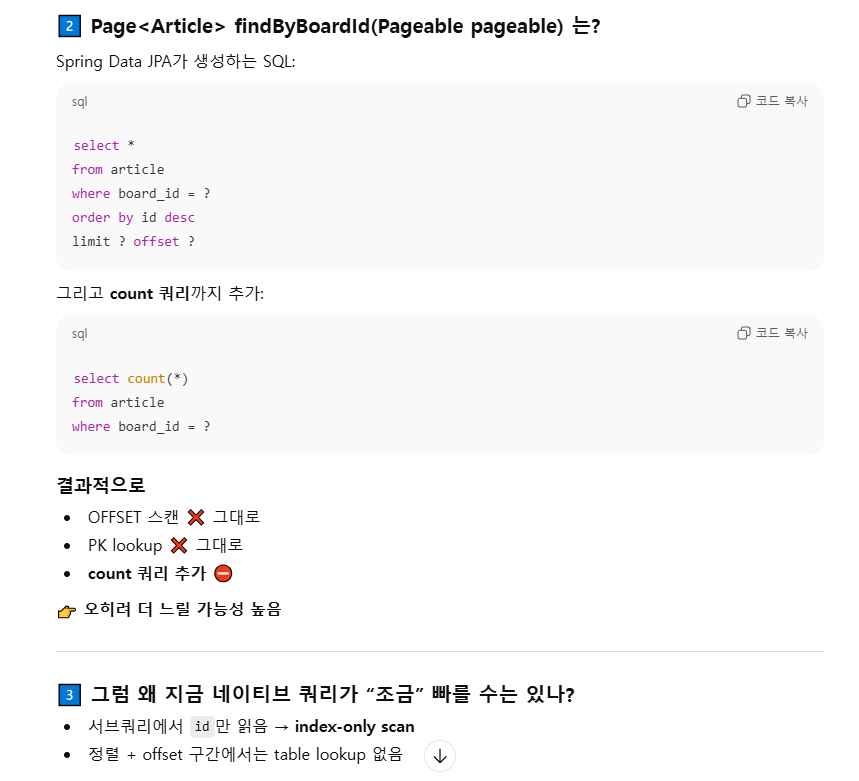
Pageable은 우리가 만든것처럼 서브쿼리로 커버링 인덱스를 사용하는 쿼리를 만들지 않기 때문에 느리다.
이런 식으로 우리가 직접 특정 컬럼 기반으로 인덱스를 만들어주고 그에 맞춰서 쿼리를 작성해주면 더 빠른 조회가 가능하다.
@Query(
value = "select count(*) from (" +
" select id from article where board_id = :boardId limit :limit" +
") t",
nativeQuery = true
)
Long count(@Param("boardId") Long boardId, @Param("limit") Long limit);그리고 count도 커버링 인덱스 서브쿼리를 쓰는 방식으로 특정 개수 전까지만 세도록 한다.
이 함수를 만드는 이유는 게시글 목록에서 "다음" 버튼을 활성화해야 하는지를 계산해야 하기 때문이다.
@Slf4j
@SpringBootTest
@Import(SecurityTestConfiguration.class)
@ActiveProfiles("test")
public class ArticleRepositoryQueryTest {
@Autowired
ArticleRepository articleRepository;
@Test
void findAllTest() {
List<Article> articles = articleRepository.findAll(1L, 1499970L, 30L);
log.info("articles.size = {}", articles.size());
for (Article article : articles) {
log.info("article = {}", article);
}
}
@Test
void countTest() {
Long count = articleRepository.count(1L, 10000L);
log.info("count = {}", count);
}
}
테스트도 만들어준다.
기존에 데이터를 주입해놓은 채로 써야 한다.
@DataJpaTest를 쓰면 h2를 자동으로 쓰기 때문에 @SpringBootTest로 했다.
이 테스트는 assert를 통해 체크하는 것이 아니고 그냥 로그를 통해서 확인하는 방식으로 수행했다.
성능 테스트하겠다고 일반 JPA 메서드 따로 만들어두고 비교하는것도 과한 일 같고.
실무에서 성능 테스트를 수행하는 방법이 있을 것 같기는 한데.
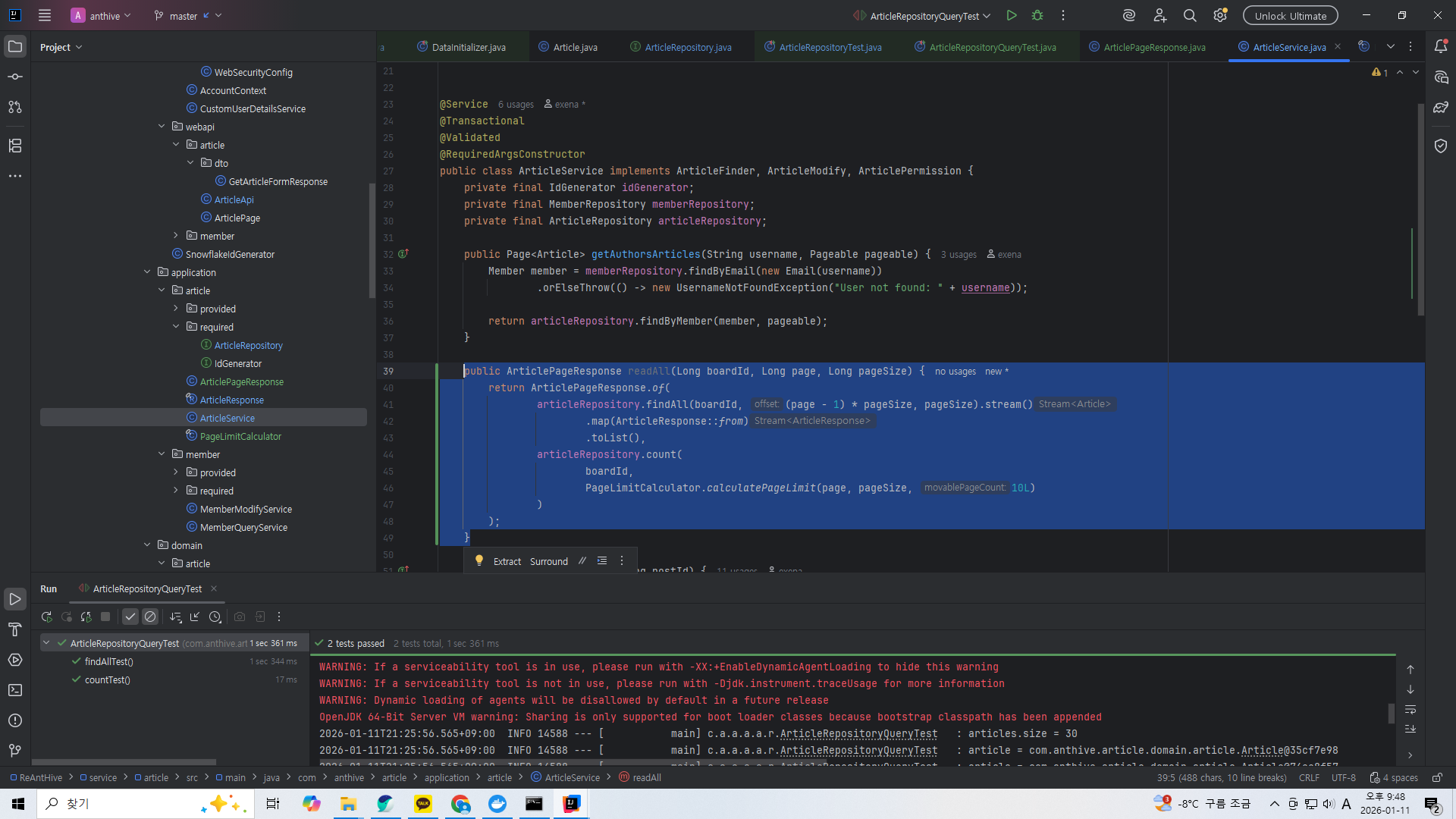
public ArticlePageResponse readAll(Long boardId, Long page, Long pageSize) {
return ArticlePageResponse.of(
articleRepository.findAll(boardId, (page - 1) * pageSize, pageSize).stream()
.map(ArticleResponse::from)
.toList(),
articleRepository.count(
boardId,
PageLimitCalculator.calculatePageLimit(page, pageSize, 10L)
)
);
}리포지토리에 만든 두 쿼리 함수를 사용해서 게시글 목록 페이지를 조회하는데 쓸 서비스단의 함수를 만들어주자.
인풋을 통해 몇번째 페이지인지, 페이지당 몇개의 게시글이 보여지는지가 들어오고 이를 통해 offset을 계산해서 쿼리함수를 동작시킨다.
count 함수는 "다음" 너머의 게시글은 필요하지 않으므로 해당 지점까지만 count 하도록 해서 성능을 높인다.
이때 "다음" 직전까지의 게시글 개수를 계산하는 함수는
@NoArgsConstructor(access = AccessLevel.PRIVATE)
public final class PageLimitCalculator {
public static Long calculatePageLimit(Long page, Long pageSize, Long movablePageCount) {
return (((page - 1) / movablePageCount) + 1) * pageSize * movablePageCount + 1;
}
}
이렇다.
그리고 리턴값으로는
@Getter
@ToString
public class ArticlePageResponse {
private List<ArticleResponse> articles;
private Long articleCount;
public static ArticlePageResponse of(List<ArticleResponse> articles, Long articleCount){
ArticlePageResponse articlePageResponse = new ArticlePageResponse();
articlePageResponse.articles = articles;
articlePageResponse.articleCount = articleCount;
return articlePageResponse;
}
}
이렇게 기존의 Page 객체를 대체할 클래스를 만들어주자.
@GetMapping("/v1/articles")
public ArticlePageResponse readAll(
@RequestParam("boardId") Long boardId,
@RequestParam("page") Long page,
@RequestParam("pageSize") Long pageSize
) {
return articleService.readAll(boardId, page, pageSize);
}API 컨트롤러에서 이제 이 응답을 반환하도록 해주자.
@Test
void readAllTest() {
ArticlePageResponse response = restClient.get()
.uri("/api/v1/articles?boardId=1&pageSize=30&page=50000")
.headers(h -> h.setBasicAuth(member.getEmail().address(), member.getPasswordHash()))
.retrieve()
.body(ArticlePageResponse.class);
System.out.println("response.getArticleCount() = " + response.getArticleCount());
for (ArticleResponse article : response.getArticles()) {
System.out.println("articleId = " + article.id());
}
}테스트 코드도 작성해주자.
인강 내용만 따라하고 끝나는 것은 아쉬우니
public Page<Article> readAllPage(
Long boardId,
Long page,
Long pageSize
) {
long offset = (page - 1) * pageSize;
List<Article> content =
articleRepository.findAll(boardId, offset, pageSize);
long total =
articleRepository.count(
boardId,
PageLimitCalculator.calculatePageLimit(page, pageSize, 10L)
);
PageRequest pageRequest =
PageRequest.of(page.intValue() - 1, pageSize.intValue());
return new PageImpl<>(content, pageRequest, total);
}서비스단에서 PageImpl객체를 반환하도록 조금만 수정해보자.
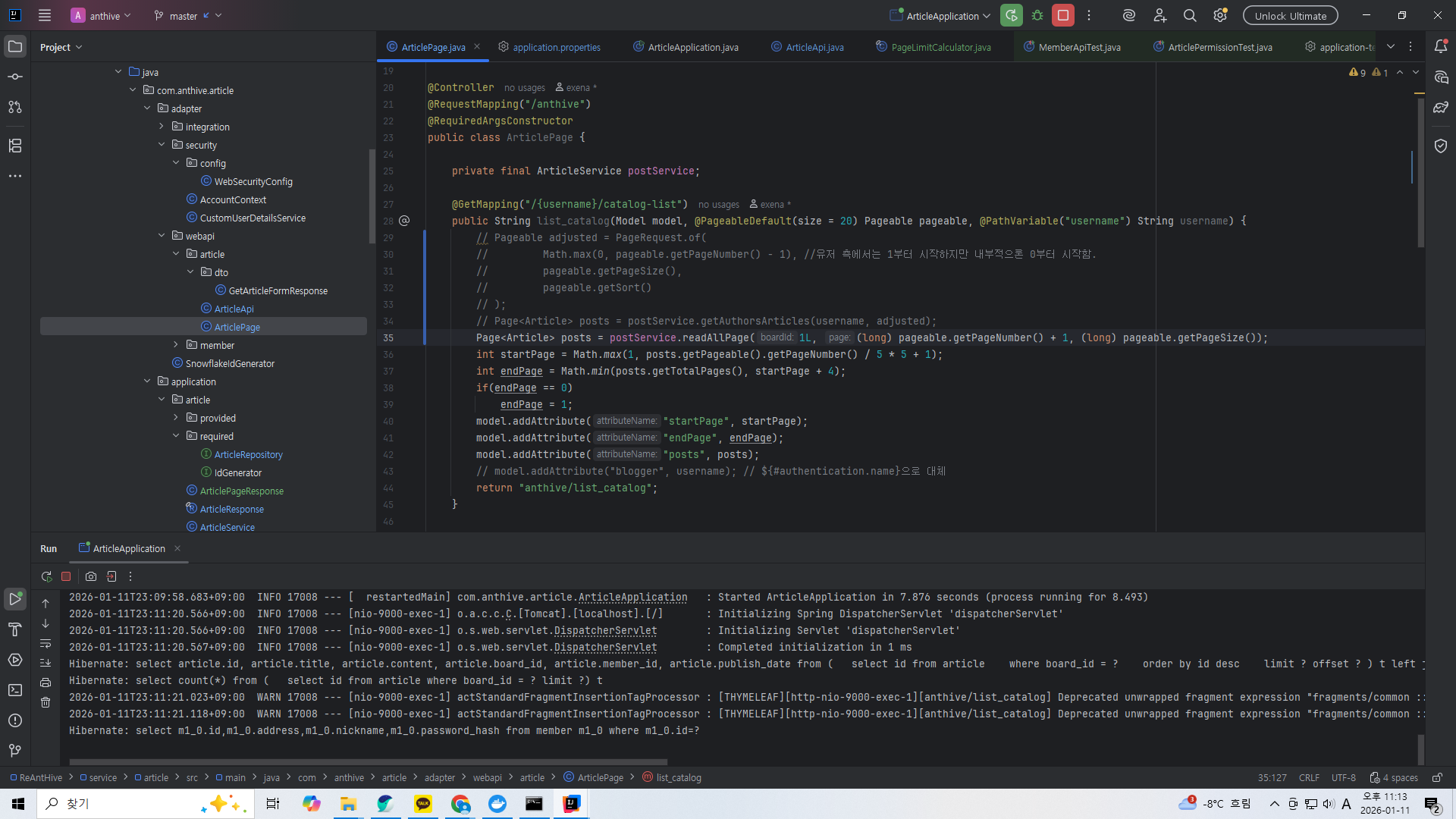
기존에 만들었던 컨트롤러에서 이부분만 대체해주면...
그리고 설정에서 운영도 테스트 db를 사용하도록 바꿔주면...
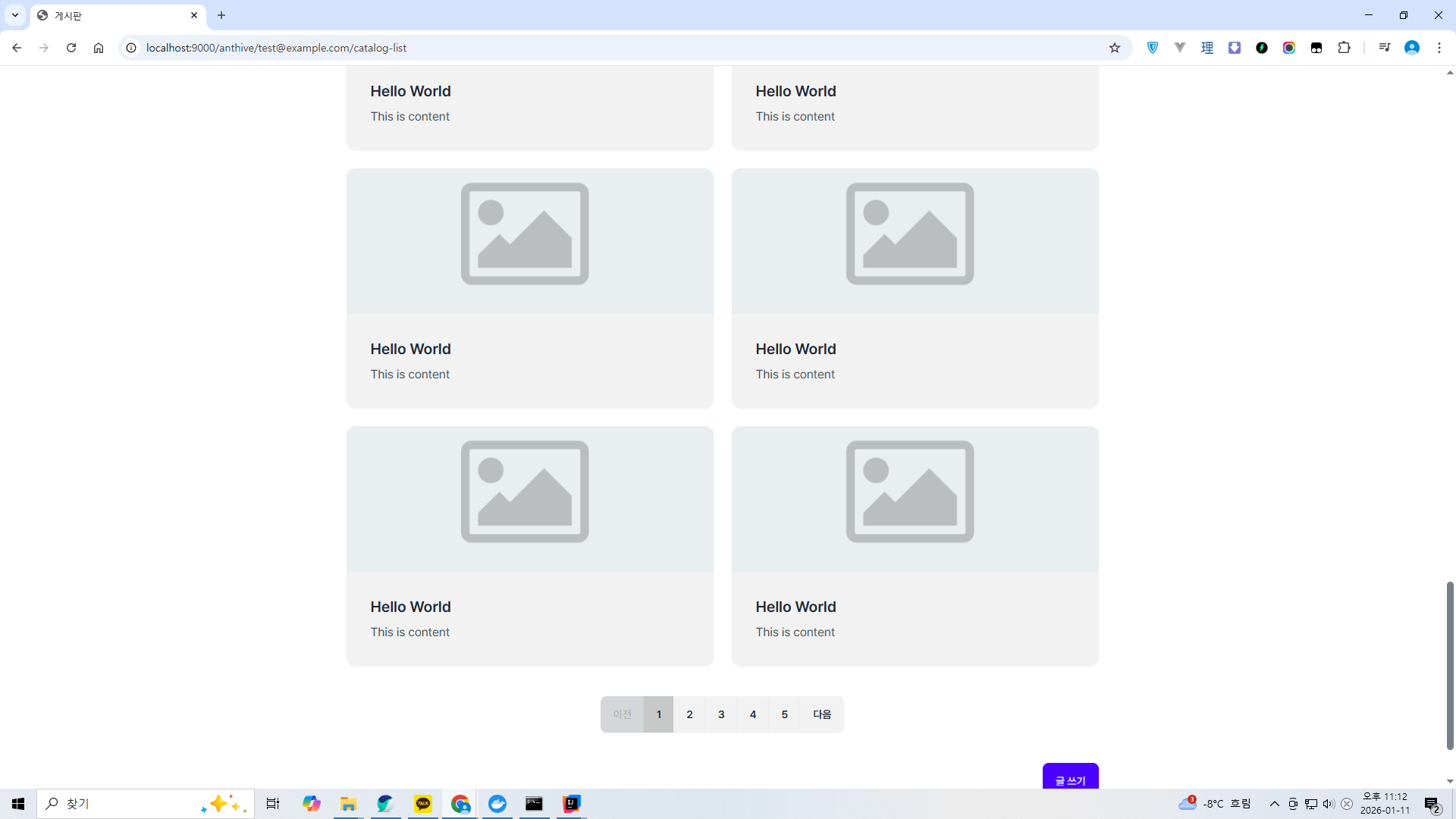
삽입해놓은 게시글이 나오는 것을 볼 수 있다.

어째선지 마지막 페이지는 빈 페이지가 나온다.
그리고 뒤로 갈수록 느려진다. 이건 offset 쿼리라서 어쩔 수 없다고 이미 말했지만.
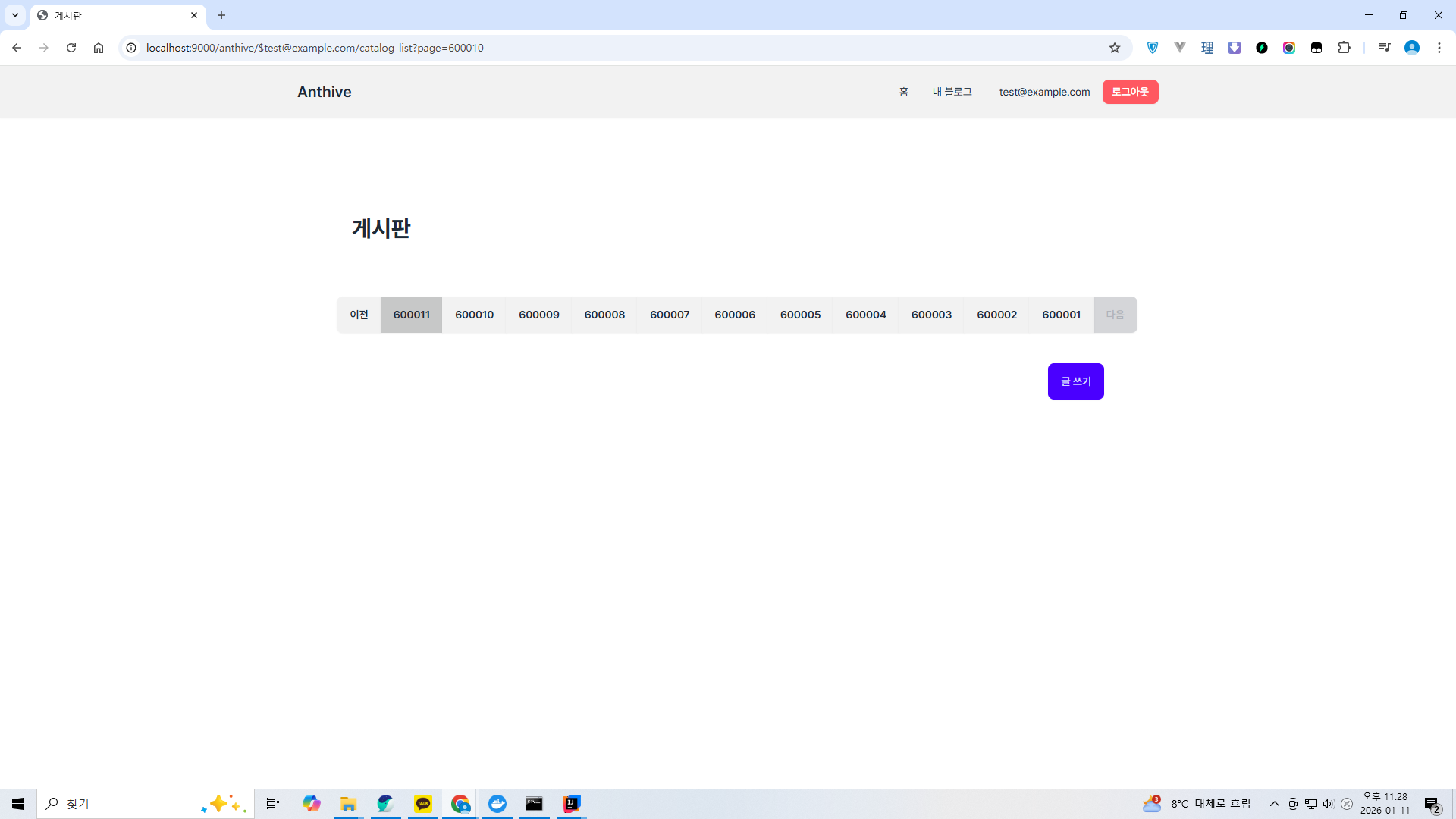

게다가 마지막 페이지보다 더 큰 페이지를 입력하자 이상한 에러가 발생했다. 리스트가 역순으로 나온다.
그것보다 더 큰 페이지를 입력하면 아예 리스트가 여의봉마냥 길어진다.
챗지피티에 물어보니 lastPage = ceil(total / size) 계산으로 인해서 마지막 페이지가 빈칸으로 나오는 것이고 MySQL의 로직상 offset이 데이터 개수를 초과하면 backward scan이 발생한다고 하네.
이 부분은 나중에 고치던가 해야겠다.
'스프링 부트로 블로그 서비스 개발하기' 카테고리의 다른 글
| 댓글 기능 - 새 모듈 만들고 설정 (0) | 2026.01.13 |
|---|---|
| 포스트 CRUD 기능 - 게시글 목록의 무한 스크롤 조회 (0) | 2026.01.12 |
| 포스트 CRUD 기능 - 인덱스 생성 및 커버링 인덱스 (1) | 2026.01.11 |
| 포스트 CRUD 기능 - 쓰레드풀을 써서 게시글 대량 삽입 테스트 (0) | 2026.01.10 |
| 포스트 CRUD 기능 - Snowflake로 게시글 id 만들기 (0) | 2026.01.07 |