
인덱스를 생성한다.
create index idx_board_id_article_id on article(board_id asc, id desc);
게시판 id로 내림차순하고 게시글 id로 오름차순해서 정렬하도록 한다.
방금 생성한 인덱스를 기반으로 정렬(order by)하고 필터링(where)해서 조회해보자.
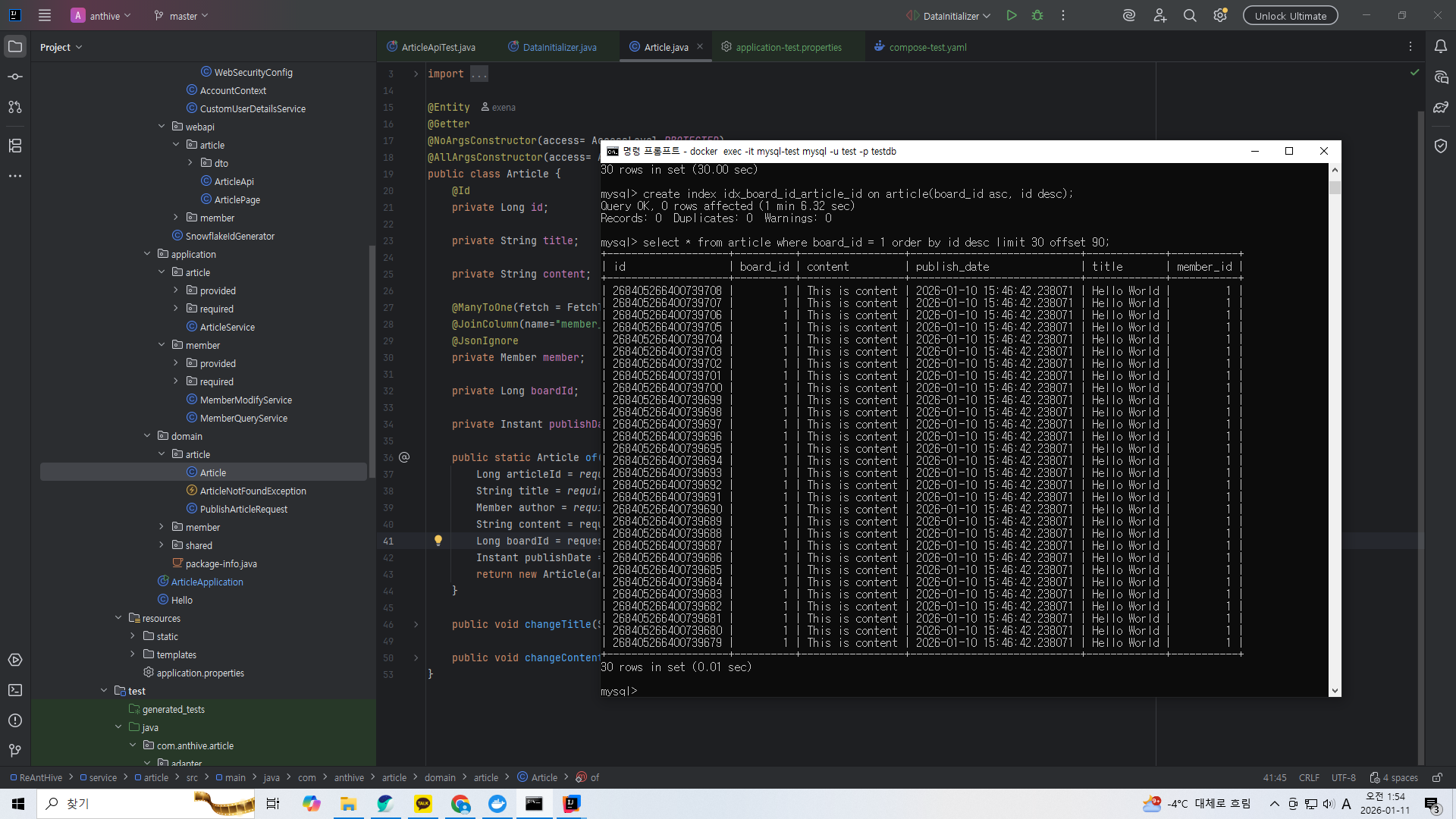
select * from article where board_id = 1 order by id desc limit 30 offset 90;
0.01초만에 생성되는 것을 볼 수 있다.
사실 기본 id로 정렬하는 건 따로 인덱스를 안만들어도 기본 인덱스가 id라서 원래 빠르긴 한데.
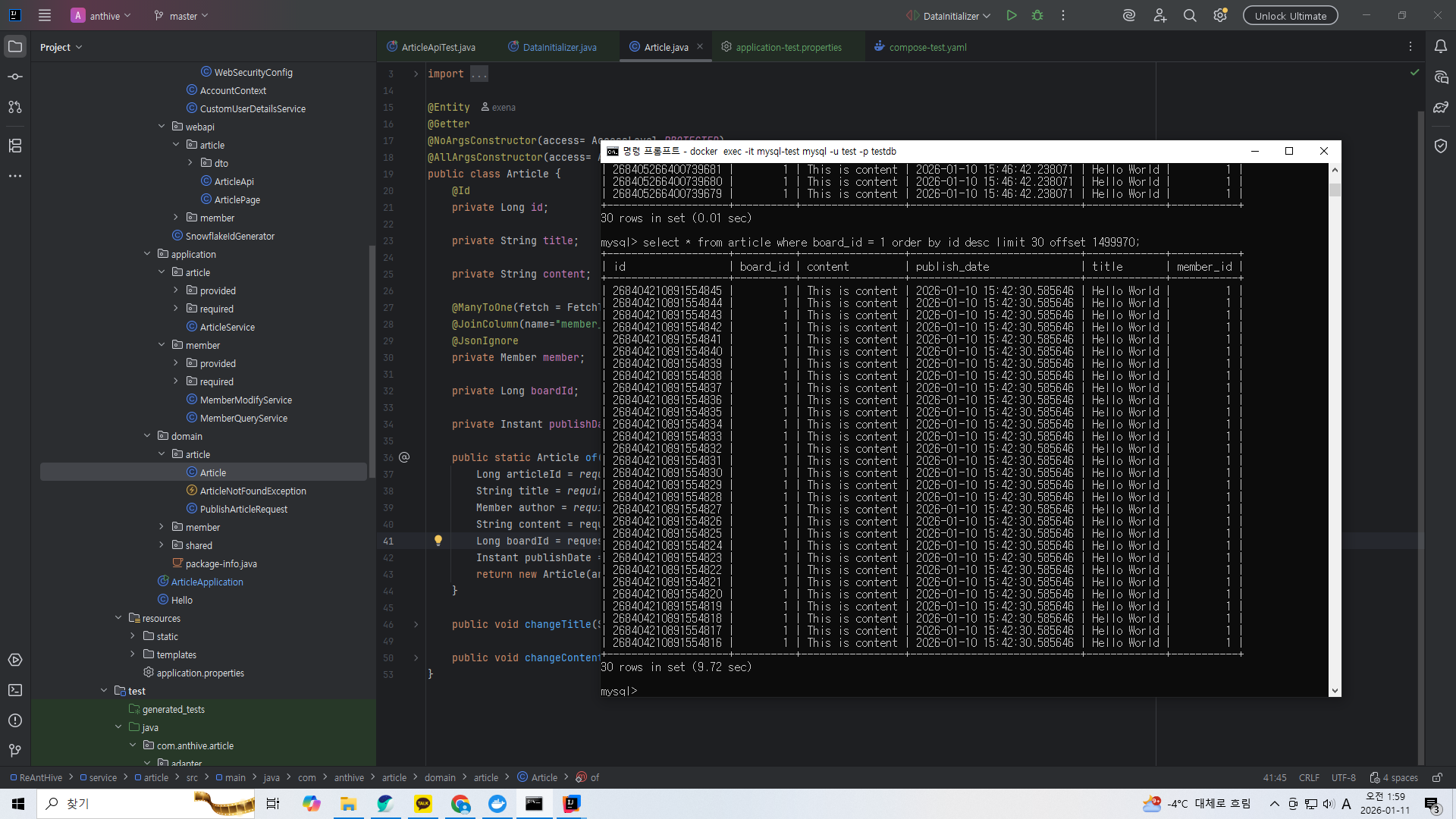
select * from article where board_id = 1 order by id desc limit 30 offset 1499970;
하지만 offset이 커지니까 다시 오래 걸리는 것을 볼 수 있다.
왜냐하면 offset은 읽는걸 스킵하는게 아니라 읽고 버리는것이기 때문이다.
우리가 만든 인덱스를 통해서 데이터의 id를 알아낸 뒤 다시 기본 인덱스를 통해서 접근해서 읽기 때문에 오래 걸린다.

하지만 offset을 사용하지 않고 where을 통해 접근하는 방법이 있다.
하지만 이 방식은 어느 지점부터 읽고 싶은지 id를 지정해줘야 하기 때문에 임의 페이지에 바로 접근하는 것이 어렵다.
이건 이후 포스팅에서 설명하도록 하고 일단은 인강에서 나오는 순서대로 커버링 인덱스 방식부터 설명하겠다.
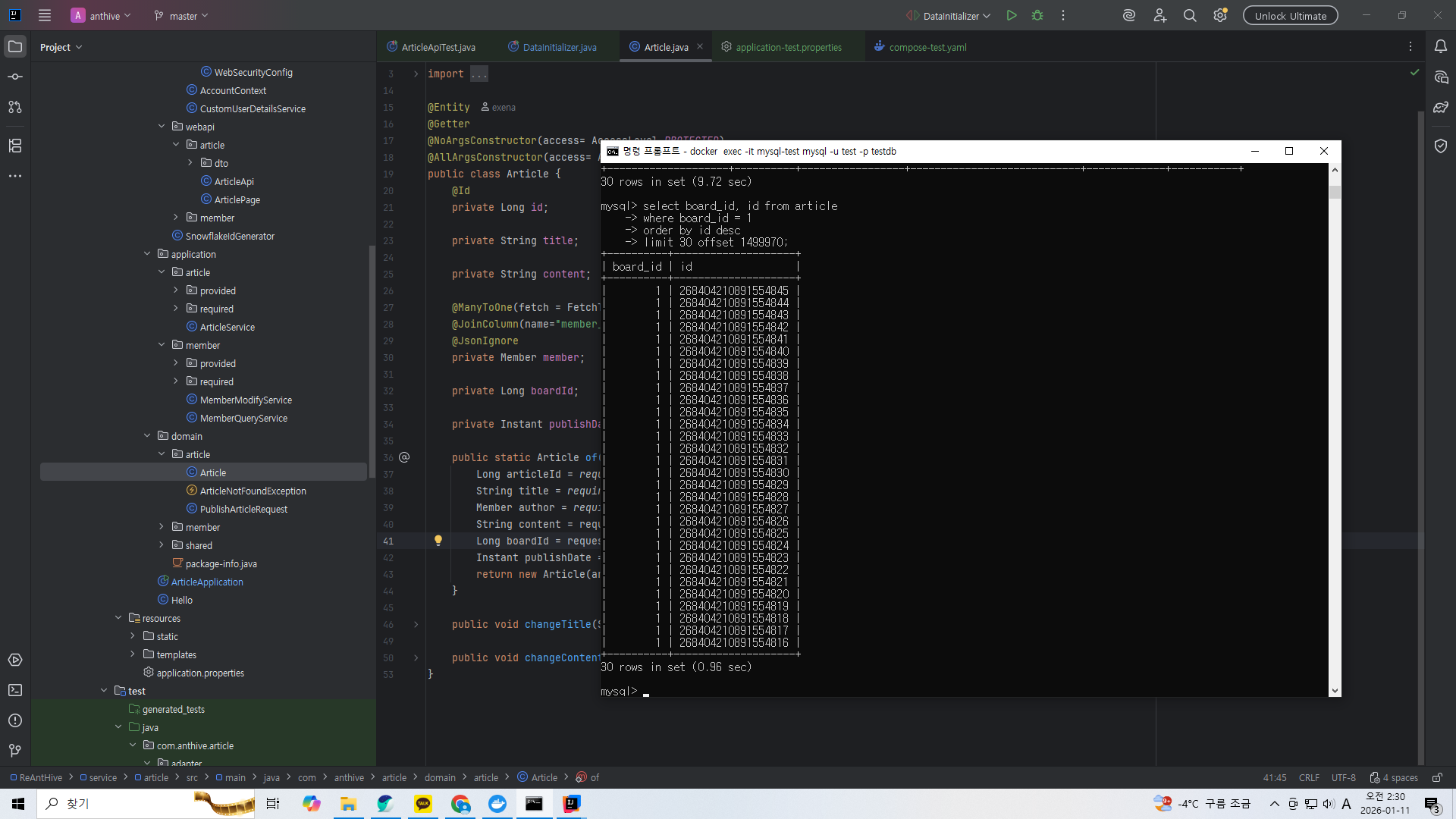
select board_id, id from article where board_id = 1 order by id desc imit 30 offset 1499970;
이번엔 select * 가 아니라 그냥 board_id와 id만 읽도록 했더니, 그건 우리가 만든 인덱스에 이미 포함되어 있는 정보이기 때문에 기본 인덱스까지 접근하지 않아서 빠르게 수행되었다.
이걸 응용해보자.
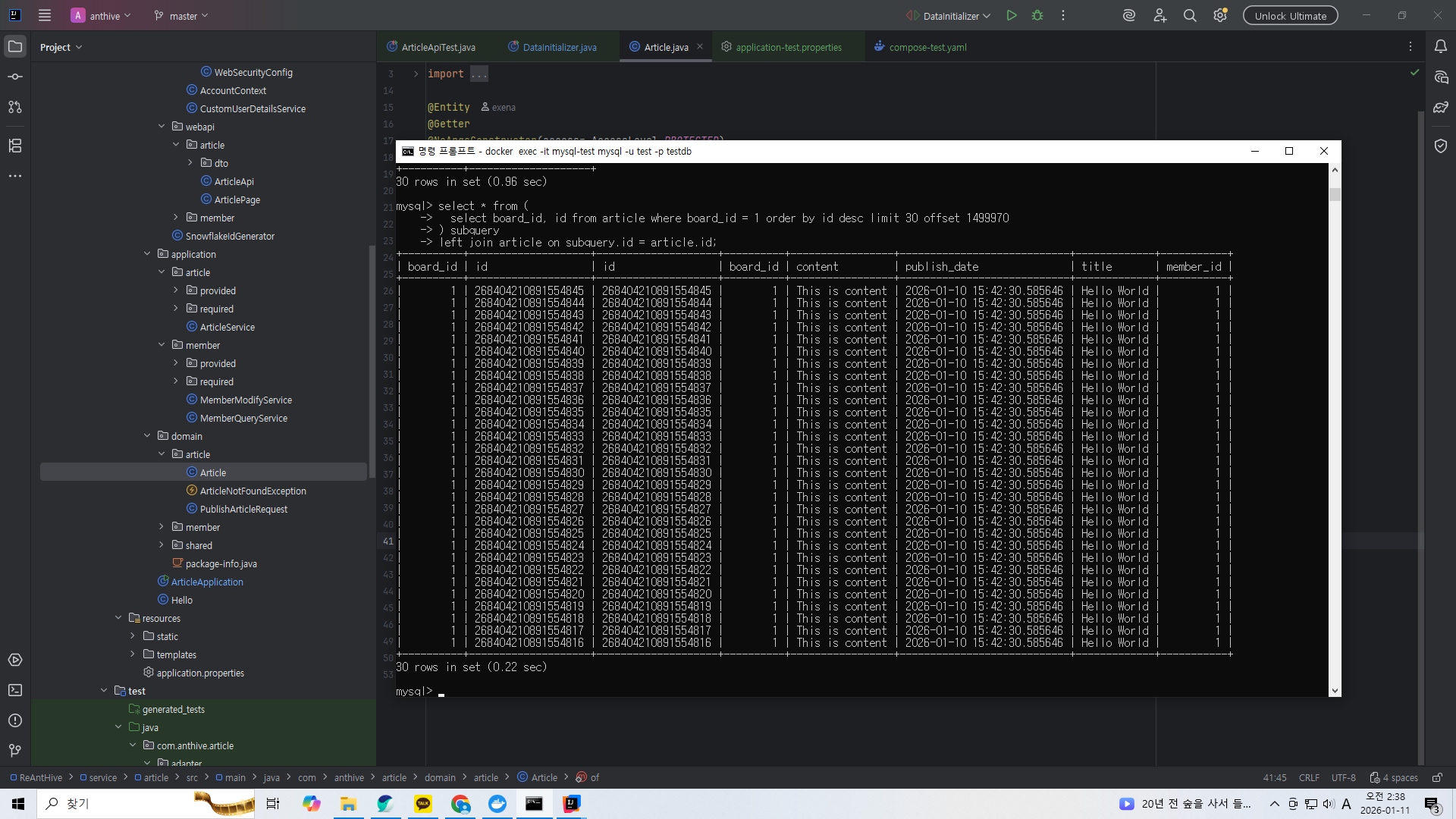
select * from (
select board_id, id from article where board_id = 1 order by id desc limit 30 offset 1499970
) subquery
left join article on subquery.id = article.id;
방금 썼던 쿼리를 서브쿼리로 써서 필요한 id를 조회한 뒤 그 id로 테이블에서 데이터를 읽는 것이다.
훨씬 빠르게 수행되는 것을 볼 수 있다.
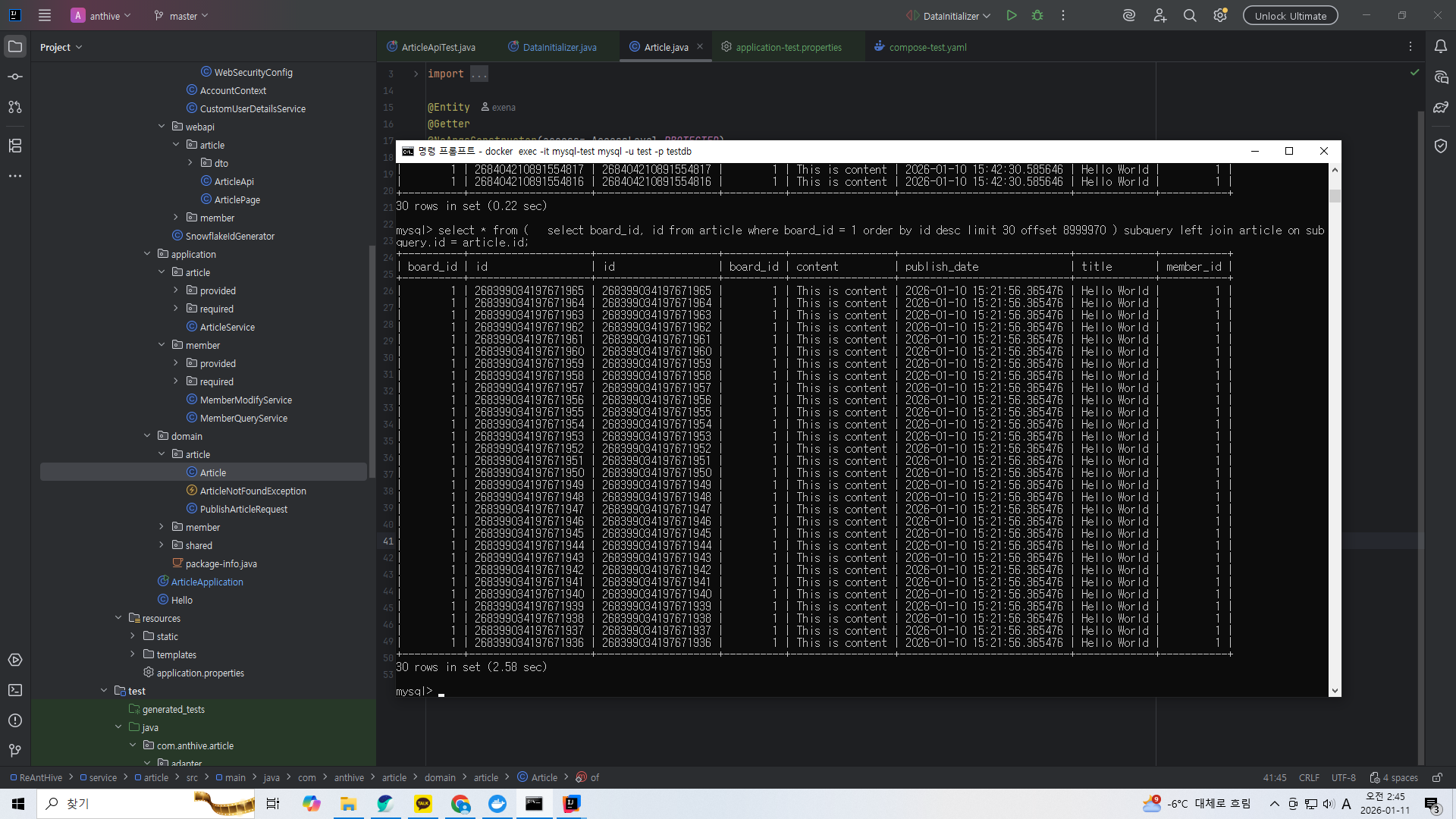
하지만 offset이 더 커진다면 이 방식도 결국 느려진다. 기본 인덱스까진 안가지만 우리가 만든 인덱스를 계속 읽기 때문이다.
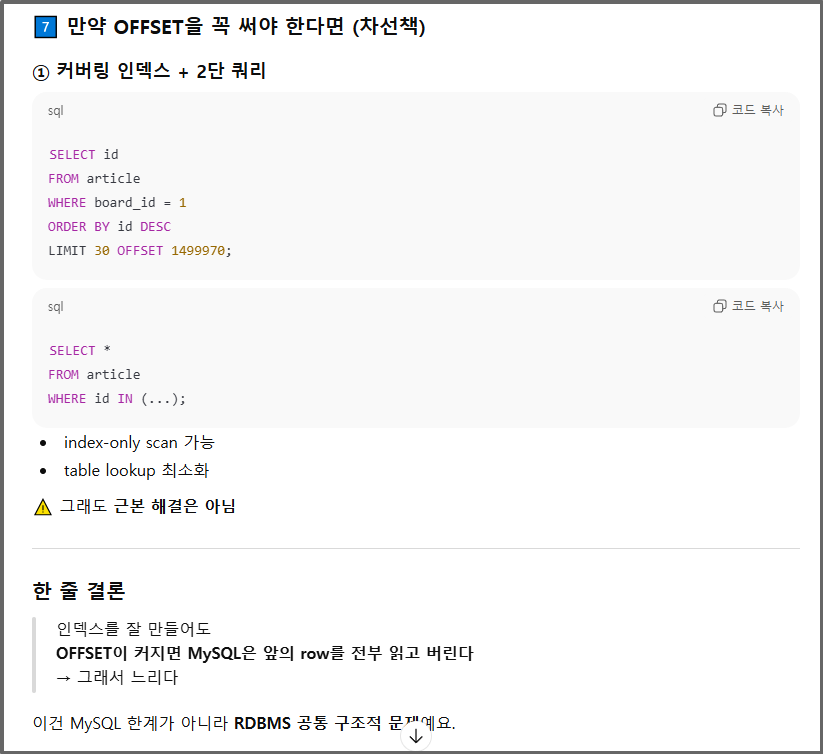
결국 근본 해결책은 아닌 것.
이를 해결하려면 간단하게는 게시글을 1년 단위로 테이블을 분리하거나 할 수도 있고, 위에서 본 where방식으로 접근할 수도 있다.
하지만 아까도 말했다시피 where 방식으로 접근하는 것은 임의 페이지에 접근하는 것이 어렵다.
이 부분은 서비스를 설계할 때 고민을 좀 해야할 부분인 듯.

위에서 보았듯이 count(*)를 하게 되면 시간이 오래 걸린다.
이건 직접 데이터를 읽기 때문은 아니다. 그냥 count에만 쓰이기 때문에 커버링 인덱스로 처리함에도 인덱스를 하나하나 읽느라 오래 걸리는 것이다.

같은 쿼리를 다시 수행하면 시간이 줄어드는 걸 볼 수 있는데 이건 아마 캐시가 동작해서인듯.

하지만 모든 게시글의 개수가 필요한 게 아니라 그냥 게시글이 특정 개수 이상인지만 알고 싶다면?
그럼 limit을 통해서 그 특정 개수까지만 읽는 것이 가능하다.
집계함수 count 자체에 limit을 거는것은 안되기에 서브쿼리에서 limit으로 데이터를 가져온 후 그 개수를 count로 반환하면 된다.
'스프링 부트로 블로그 서비스 개발하기' 카테고리의 다른 글
| 포스트 CRUD 기능 - 게시글 목록의 무한 스크롤 조회 (0) | 2026.01.12 |
|---|---|
| 포스트 CRUD 기능 - 커버링 인덱스 방식으로 게시글 목록의 페이지 조회 쿼리 최적화 (0) | 2026.01.11 |
| 포스트 CRUD 기능 - 쓰레드풀을 써서 게시글 대량 삽입 테스트 (0) | 2026.01.10 |
| 포스트 CRUD 기능 - Snowflake로 게시글 id 만들기 (0) | 2026.01.07 |
| 대규모 시스템 설계 인강) MSA화 진행하기: 모듈 추가하고 build.gradle 분리 (0) | 2026.01.07 |